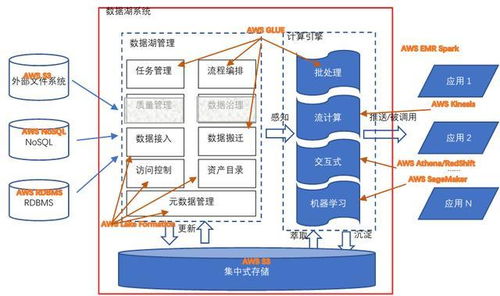
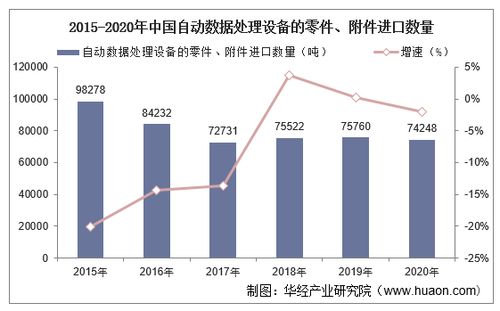
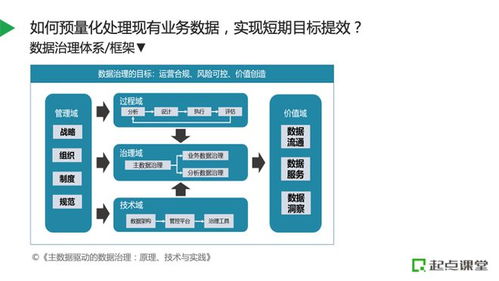
数据预处理组件 提升数据处理效率与准确性的核心引擎
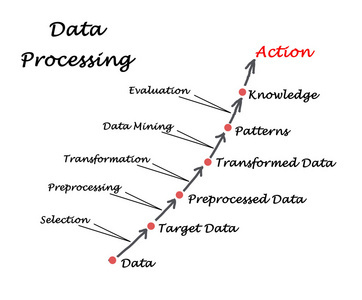
在当今数据驱动的时代,数据预处理已成为数据分析、机器学习与人工智能项目不可或缺的关键环节。作为数据处理流程的“守门员”与“净化器”,数据预处理组件负责将原始、杂乱、不一致的数据转化为干净、统一、可用于分析的格式,其质量直接决定了后续模型训练与决策分析的成败。
一、数据预处理组件的核心功能
数据预处理组件通常集成了一系列功能模块,旨在系统性地解决数据质量问题。其主要功能包括:
- 数据清洗:识别并处理缺失值、异常值(如使用均值填充、中位数替代或直接删除异常记录)以及重复数据,确保数据的完整性与一致性。
- 数据转换:对数据进行规范化或标准化处理(如Min-Max归一化、Z-Score标准化),使不同量纲或范围的指标具有可比性;可能涉及数据离散化、函数变换等操作。
- 数据集成与合并:将来自不同源头、格式各异的数据进行整合,解决实体识别冲突、属性冗余等问题,形成统一的数据视图。
- 特征工程:创造新的、更具预测力的特征(如通过组合、分解现有特征),或进行特征选择,剔除不相关或冗余的特征,以降低模型复杂度并提升性能。
- 数据降维:当数据特征维度极高时(如文本、图像数据),采用主成分分析(PCA)、线性判别分析(LDA)等方法减少特征数量,保留主要信息,提高计算效率。
二、技术实现与工具支持
现代数据预处理组件的实现高度依赖于强大的编程语言与开源库。Python因其丰富的数据科学生态系统成为首选,常用库包括:
- Pandas:提供高效的数据结构(如DataFrame)和灵活的数据清洗、转换、合并功能。
- NumPy:支持高性能的数值计算,是许多数据操作的基础。
- Scikit-learn:提供了丰富的预处理工具,如标准化、归一化、编码、特征选择与降维等模块。
- 专用ETL工具:如Apache Spark、Talend、Informatica等,适用于大规模、分布式的数据预处理任务。
三、最佳实践与挑战
1. 理解业务与数据:预处理策略需紧密结合具体业务场景与数据特性,避免盲目应用标准化流程。
2. 流程自动化与可复现性:构建自动化、流水线化的预处理流程,并确保每一步骤可追溯、可复现,这对于持续集成与模型迭代至关重要。
3. 应对挑战:数据预处理常面临数据规模巨大(大数据)、数据非结构化(文本、图像)、数据漂移(线上分布与训练集不一致)等挑战,需要结合分布式计算、自然语言处理、计算机视觉及在线学习等技术应对。
四、结论
数据预处理组件是连接原始数据与高级分析应用的桥梁。一个设计精良、功能全面的预处理组件不仅能大幅提升数据处理效率,减少人工干预,更能从根本上保障数据质量,为后续的建模与分析工作奠定坚实可靠的基础。随着数据形态日益复杂与处理需求不断升级,持续优化与创新数据预处理技术,将是释放数据价值、驱动智能决策的核心所在。
如若转载,请注明出处:http://www.wsxvr.com/product/8.html
更新时间:2026-06-06 02:05:50