异构大数据环境下的数据管道与存储服务构建策略
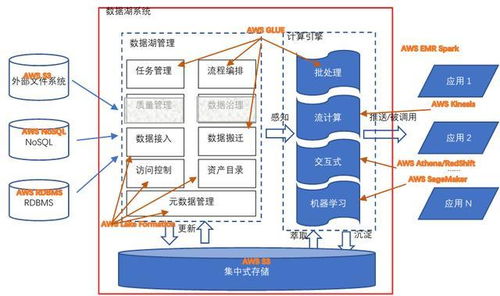
随着企业数据源与处理技术的多样化,构建适应异构大数据运行环境的数据管道与存储服务已成为现代数据架构的核心挑战。异构环境通常包含传统关系型数据库、NoSQL数据库、数据湖、云存储、实时流数据源以及各类专有系统,数据格式、协议与处理引擎各异。要在此环境下高效、可靠地流动与存储数据,需采用系统化的架构设计。
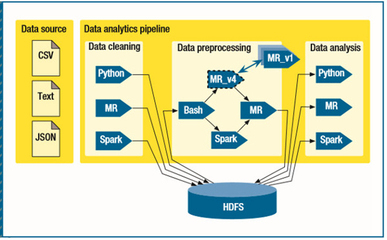
数据管道的构建应遵循解耦与标准化原则。通过引入统一的消息中间件(如Apache Kafka、RabbitMQ)或数据集成平台(如Apache NiFi、Airbyte),可将不同数据源的抽取过程标准化。管道设计需支持批处理与流处理的融合,例如采用Lambda架构或更现代的Kappa架构,确保实时与历史数据的一致性处理。针对异构数据格式(JSON、Avro、Parquet等),管道中应集成模式注册与管理服务(如Confluent Schema Registry),实现数据的自描述与兼容性验证。
存储服务的选择需兼顾性能、成本与可扩展性。在异构环境中,单一存储方案往往难以满足所有需求,因此常采用分层存储策略:
1. 热数据层:使用高性能数据库(如ClickHouse、内存数据库)或分布式文件系统(如HDFS、云对象存储)支持实时查询。
2. 温数据层:通过数据湖(如Apache Iceberg、Delta Lake)统一存储多格式数据,提供ACID事务与版本管理,便于分析任务。
3. 冷数据层:利用低成本对象存储或磁带库归档历史数据,并通过生命周期策略自动迁移。
关键是在各层间建立无缝的数据流动机制,例如通过管道将实时数据流入热层,定期压缩至温层,再按策略归档至冷层。
元数据管理与数据治理不可或缺。在异构环境中,需建立统一的元数据目录(如Apache Atlas、Amundsen),追踪数据血缘、质量指标与访问权限。存储服务应集成加密、审计与合规性功能,尤其当数据跨云或混合部署时,需确保符合GDPR等法规要求。
运维监控是保障管道与存储可靠性的基石。通过指标收集(如Prometheus)、日志聚合(如ELK Stack)与自动化告警,可实时监测数据延迟、吞吐量及存储健康状态。容器化(如Kubernetes)与基础设施即代码(IaC)工具能提升环境部署的一致性,降低异构环境的管理复杂度。
构建异构大数据环境的数据管道与存储服务,需以灵活架构为基础,结合标准化接口、分层存储与强治理能力,方能在数据多样性中实现高效、安全的价值提取。
如若转载,请注明出处:http://www.wsxvr.com/product/11.html
更新时间:2026-06-06 14:14:08