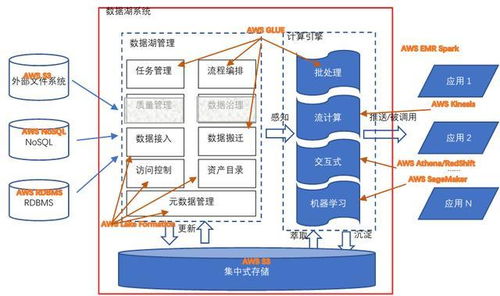
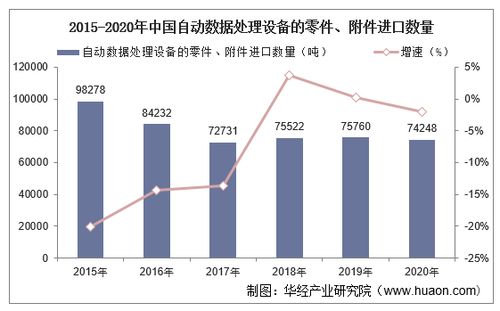
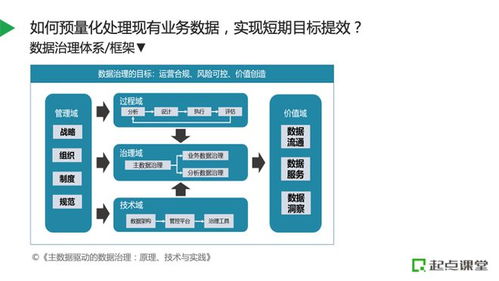
图中的数据处理系统存储服务 架构、优势与应用实践
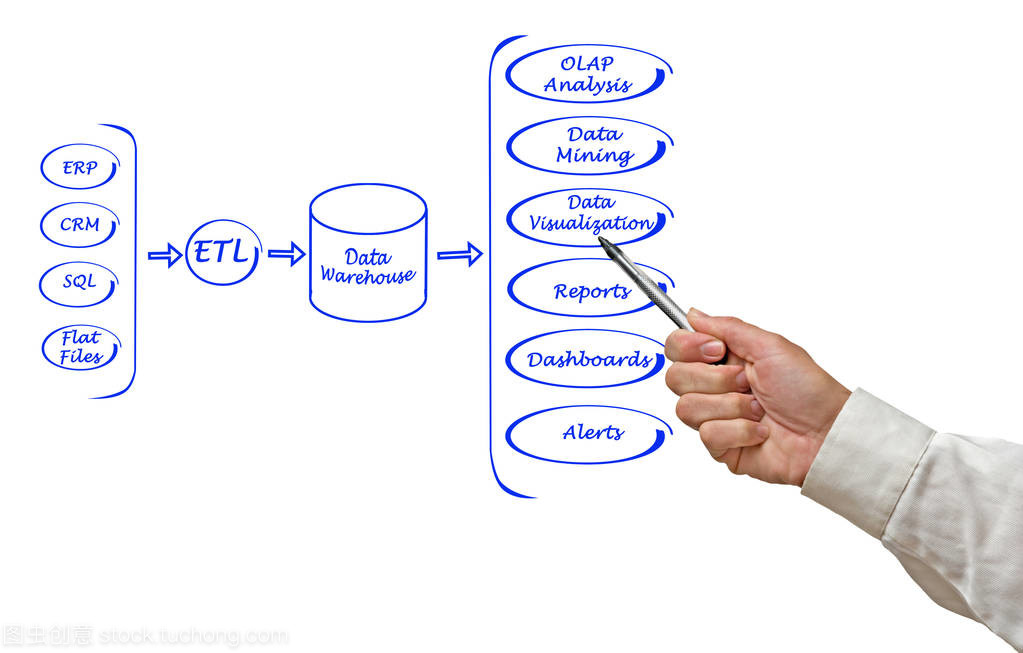
在当今数据驱动的时代,高效、可靠的数据处理系统是各类业务与应用的核心支柱。其中,存储服务作为数据处理系统的基石,负责数据的持久化、管理与访问,其设计与性能直接影响整个系统的效率与可靠性。本文将以“图中的数据处理系统”为背景,深入探讨其存储服务的核心架构、关键优势及典型应用实践。
一、 存储服务的核心架构
在一个典型的图数据处理系统中,存储服务通常采用分层或混合架构,以平衡性能、可扩展性与成本。其核心组件一般包括:
- 图数据模型层:这是存储的逻辑核心。它定义了节点(实体)、边(关系)及其属性(键值对)的组织方式。常见的模型有属性图模型(如Neo4j、Amazon Neptune所采用),它直观地映射现实世界关系,支持复杂的关联查询。
- 存储引擎层:负责将逻辑图模型持久化到物理存储介质。根据性能需求,可能采用:
- 原生图存储:专为图结构设计,将节点和边的邻接关系紧密存储(如邻接列表),使得遍历查询(如“朋友的朋友”)极快。
- 基于KV/列存的存储:将图数据序列化为键值对或列族,构建在HBase、Cassandra等之上,利于水平扩展和大规模数据存储。
- 混合存储:结合多种引擎,例如将热点图结构存入内存,将全量数据存入磁盘或分布式文件系统(如HDFS)。
- 索引与缓存层:
- 索引服务:为节点和边的属性建立索引(如B树、LSM树、倒排索引),加速基于属性的点查和范围查询,避免全图扫描。
- 缓存服务:利用内存(如Redis)缓存频繁访问的子图、查询结果或元数据,显著降低访问延迟。
- 分布式协调与服务层:在分布式系统中,此层(常利用ZooKeeper、etcd等)负责元数据管理、集群状态协调、服务发现与负载均衡,确保存储服务的高可用与一致性。
二、 存储服务的关键优势
图数据处理系统的存储服务,相较于传统关系型或简单KV存储,在处理关联数据时展现出独特优势:
- 关联查询高效性:通过原生存储邻接关系,能够以常数时间复杂度跳转至相邻节点,使多跳查询、路径发现、社群检测等操作极为迅速,避免了复杂且耗时的JOIN操作。
- 灵活的数据模式:属性图模型支持动态添加节点、边及其属性,无需预定义严格的表结构,适应业务快速变化和半结构化数据。
- 强大的可扩展性:通过图分区策略(如基于边切割或节点切割),结合分布式存储引擎,可以实现存储与计算的水平扩展,以应对海量图数据。
- 内置关系语义:存储本身即承载了关系语义,使得诸如社交网络、推荐系统、欺诈检测等高度依赖关系的应用逻辑更直观、更易于实现。
三、 应用实践与挑战
图数据处理系统的存储服务已广泛应用于:
- 社交网络:存储用户关系,实现好友推荐、影响力分析。
- 金融风控:存储账户、交易实体及其复杂资金网络,实时检测欺诈环路。
- 知识图谱:存储实体与事实,支持语义搜索与智能推理。
- IT运维:存储设备、服务间的依赖图,实现根因分析。
在实践中也面临挑战:
- 分区与数据局部性:如何在分布式环境下有效分割图数据,最小化跨节点查询,是一大难题。
- 一致性与性能权衡:在分布式场景下,保证跨分区图事务的强一致性可能牺牲性能,需要根据场景选择合适的一致性模型。
- 存储与计算协同:需要设计高效的存储格式,以减少数据序列化/反序列化开销,并与图计算框架(如Pregel、GraphX)紧密集成。
###
图中的数据处理系统的存储服务远非简单的数据“仓库”,它是一个为复杂关系查询和高并发访问而深度优化的专门子系统。其架构设计需在查询性能、扩展性、灵活性和成本之间取得精巧平衡。随着图技术在更多领域的渗透,对更智能、更自适应、云原生的图存储服务的需求将持续增长,推动该领域不断向前演进。
如若转载,请注明出处:http://www.wsxvr.com/product/15.html
更新时间:2026-06-06 08:13:49